宾夕法尼亚州立大学跨学科团队的研究表明,一种新颖的、受人类启发的训练人工智能(AI)系统识别物体和导航周围环境的方法可以为开发更先进的AI系统以探索极端环境或遥远世界奠定基础。
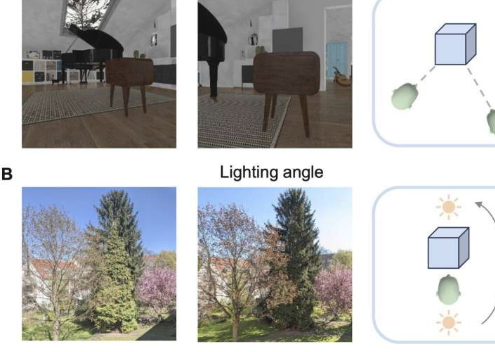
在生命的最初两年里,儿童接触到的物体和面孔相对较少,但视角和光照条件各不相同。受这一发展洞察的启发,研究人员引入了一种新的机器学习方法,利用有关空间位置的信息更有效地训练人工智能视觉系统。
他们发现,用新方法训练的人工智能模型比基础模型高出14.99%。他们在《Patterns》杂志5月刊上发表了他们的研究成果。
“目前,人工智能的方法是使用来自互联网的大量随机照片集进行训练。相比之下,我们的策略则受到发展心理学的影响,该心理学研究儿童如何看待世界,”本文第一作者、宾夕法尼亚州立大学信息科学与技术学院博士生朱丽珍说道。
研究人员开发了一种新的对比学习算法,这是一种自我监督学习方法,其中人工智能系统学习检测视觉模式,以识别两幅图像是否是同一基础图像的衍生品,从而产生正对。然而,这些算法通常将从不同角度拍摄的同一物体的图像视为单独的实体,而不是正对。
研究人员表示,考虑到位置等环境数据,人工智能系统可以克服这些挑战,并且无论相机位置或旋转、光照角度或条件以及焦距或变焦如何变化,都能检测到正对。
“我们假设婴儿的视觉学习取决于位置感知。为了生成具有时空信息的自我中心数据集,我们在ThreeDWorld平台中设置了虚拟环境,这是一个高保真、交互式的3D物理模拟环境。这使我们能够操纵和测量观察摄像头的位置,就像孩子在房子里走路一样,”朱补充道。
科学家们创建了三个模拟环境——House14K、House100K和Apartment14K,其中“14K”和“100K”指的是每个环境中拍摄的样本图像的大致数量。然后,他们通过模拟运行了基础对比学习模型和采用新算法的模型三次,以查看每个模型对图像的分类效果如何。该团队发现,在他们的算法上训练的模型在各种任务上都优于基础模型。
例如,在识别虚拟公寓房间的任务中,增强模型的平均准确率为99.35%,比基础模型提高了14.99%。其他科学家可以通过www.child-view.com使用这些新数据集进行训练。
“模型在新环境中使用少量数据进行学习总是很困难的。我们的工作是首次尝试使用视觉内容进行更节能、更灵活的人工智能训练,”信息科学与技术杰出教授、朱的导师JamesWang说道。
科学家表示,这项研究对于未来发展用于在新的环境中导航和学习的先进人工智能系统具有重要意义。
王说:“这种方法在资源有限的自主机器人团队需要学习如何在完全陌生的环境中导航的情况下尤其有用。”“为了为未来的应用铺平道路,我们计划改进我们的模型,以更好地利用空间信息并融入更多样化的环境。”
宾夕法尼亚州立大学心理学系和计算机科学与工程系的合作者也参与了这项研究。