达姆施塔特工业大学计算机科学系人工智能与机器学习实验室(AIML)和黑森人工智能中心(hessian.AI)的研究人员开发了一种方法,使用视觉语言模型来过滤、评估和抑制大型数据集或图像生成器中的特定图像内容。
人工智能(AI)可用于识别图像和视频中的物体。这种计算机视觉还可用于分析大量视觉数据。
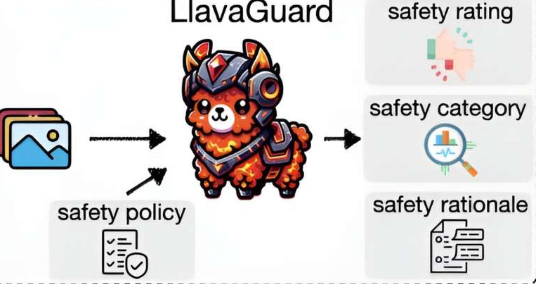
AIML的FelixFriedrich领导的研究人员开发了一种名为LlavaGuard的方法,现在可用于过滤某些图像内容。此工具使用所谓的视觉语言模型(VLM)。与只能处理文本的大型语言模型(LLM)(例如ChatGPT)相比,视觉语言模型能够同时处理和理解图像和文本内容。该研究发表在arXiv预印本服务器上。
LlavaGuard还可以满足复杂的要求,因为它的特点是能够适应不同的法律法规和用户要求。例如,该工具可以区分大麻消费等活动合法或非法的地区。LlavaGuard还可以评估内容是否适合某些年龄段,并相应地进行限制或调整。
“到目前为止,这种细粒度的安全工具仅适用于文本分析。在过滤图像时,以前只实现了‘裸体’类别,而没有实现‘暴力’、‘自残’或‘吸毒’等其他类别,”弗里德里希说。
LlavaGuard不仅会标记有问题的内容,还会通过对内容进行分类(例如“仇恨”、“非法物质”、“暴力”等)并解释为什么将其归类为安全或不安全,从而提供其安全等级的详细解释。
弗里德里希解释道:“正是这种透明度让我们的工具如此特别,对于理解和信任至关重要。”这使得LlavaGuard成为研究人员、开发人员和政治决策者的宝贵工具。
LlavaGuard研究是达姆施塔特工业大学合理人工智能(RAI)集群项目的重要组成部分,体现了该大学对推进安全和道德人工智能技术的承诺。LlavaGuard的开发旨在通过过滤训练数据并解释和证明有问题的动机的输出来提高大型生成模型的安全性,从而降低生成有害或不适当内容的风险。
LlavaGuard的潜在应用范围十分广泛,尽管该工具目前仍处于开发阶段并专注于研究,但它已经可以集成到StableDiffusion等图像生成器中,以最大限度地减少不安全内容的生成。
此外,LlavaGuard未来还可适用于社交媒体平台,通过过滤不适当的图像来保护用户,从而促进更安全的在线环境。