即使没有文本自动错误分配仍然有效
在过去十年中,自动错误分配得到了深入研究。由于文本错误报告通常描述错误现象和潜在原因,工程师高度依赖这些报告来修复错误。研究人员严重依赖错误报告中的文本内容来定位错误文件。然而,文本中的噪音意外地给自动错误分配带来了不利影响,主要是由于经典自然语言处理(NLP)技术的不足。
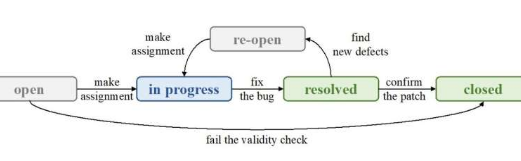
为了深入了解文本特征和名词特征的作用,李泽轩领导的研究团队在《计算机科学前沿》上发表了他们的研究成果。
该团队复现了一项NLP技术TextCNN,以了解改进的NLP技术是否能提高文本特征的性能。结果表明,即使采用相对先进的技术,文本特征也不会超过其他特征。该团队进一步探索了对错误分配方法有影响的特征,并从统计角度给出了解释。
他们发现,所选的有影响力的特征都是标称特征,这些特征反映了开发者的偏好。实验结果表明,不使用文本,标称特征就能取得有竞争力的结果。
在研究中,他们努力回答三个问题。首先,文本特征对于基于深度学习的NLP技术有多有效?他们复现了TextCNN,并将文本特征与一组名义特征的有效性进行了比较。
第二,哪些特征对缺陷分配方法有影响,为什么有影响?他们采用了包装器方法和广泛使用的双向策略。通过用不同的特征组反复训练分类器,根据度量标准判断特征的重要性。他们推测名义特征有助于缩小分类器的搜索范围,并用统计方法验证了这一推测。
第三,所选的有影响力的特征能在多大程度上改善错误分配?他们在变化的特征组上用固定分类器训练模型,并在五组特征上进行两种流行的分类器(决策树和SVM)。
实验以5个不同规模和类型的项目作为数据集,结果表明改进的NLP技术效果有限,所选关键特征在两种流行分类器下的准确率达到11–25%。
未来的工作可以集中在引入源文件以在这些有影响的特征和描述性词之间构建知识图谱,以便更好地嵌入名义特征。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
截至2024年,大众探岳GTE的售价可能会因地区、配置和促销活动而有所不同。一般来说,2024款探岳GTE的价格可能...浏览全文>>
-
关于2025款途观L的价格信息,目前还没有官方发布。不过,根据以往的市场规律和车型更新周期,我们可以大致推测...浏览全文>>
-
根据您提供的信息,2024款广东东莞威然的最低售价为22 99万元起。关于具体的落地价,需要考虑以下因素:1 ...浏览全文>>
-
根据您的描述,生活家PHEV 2025款的最低售价为 63 98万元起。如果目前有促销活动或优惠政策,建议尽快咨询...浏览全文>>
-
奔腾T99作为一汽奔腾旗下的旗舰SUV车型,凭借其大气的外观设计、丰富的科技配置以及出色的性能表现,吸引了众...浏览全文>>
-
当然可以!以下是一个简单的试驾预约流程,帮助您轻松开启智蓝G5新能源的试驾之旅:1 确定需求- 车型选择...浏览全文>>
-
特斯拉的赛博越野旅行车(Cybertruck)自发布以来就引发了广泛关注。这款车型结合了皮卡的实用性、SUV的多功能...浏览全文>>
-
江淮悍途EV是一款纯电动皮卡,如果您想预约试驾,通常需要满足以下条件和准备以下信息:1 基本条件 - 年...浏览全文>>
-
截至我所掌握的信息,瑞驰新能源的ED75 2024款具体价格和配置可能会因地区、经销商以及政策补贴的不同而有所...浏览全文>>
-
在考虑购买上汽大众ID 4 X时,了解车辆的价格以及相关的购车费用是非常重要的。以下是一些关键信息和费用明...浏览全文>>
- 山东济南途观L新能源价格大公开,买车不花冤枉钱
- 东莞途岳最新价格2025款全分析,买车不踩坑
- 济南探岳GTE新车报价2024款,换代前的购车良机,不容错过
- 郑州ID.7 VIZZION多少钱 2024款落地价,配置升级,值不值得买?
- 郑州途锐新能源最新价格2024款,优惠购车,最低售价67.98万起
- 瑞虎7 PLUS新车报价2025款,买车前的全方位指南
- 广东东莞揽巡价格走势,市场优惠力度持续加大
- 轩逸新车报价2025款,买车前的全方位指南
- 飞凡R7新车报价2025款,换代前的购车良机,不容错过
- 试驾风光ix5,轻松搞定试驾
- 捷途山海L7预约试驾,从预约到试驾的完美旅程
- 试驾E福顺,从预约到试驾的完美旅程
- 长安星卡EV多少钱?选车指南与落地价全解析
- 凯翼E5 EV多少钱?如何挑选性价比高的车
- 标致408X预约试驾,快速操作,轻松体验驾驶乐趣
- 试驾星际牛魔王,新手必看的操作流程
- 岚图汽车岚图梦想家试驾预约,轻松几步,畅享豪华驾乘
- 影豹多少钱?全方位对比助你选车
- 豪运最新价格2023款,豪华配置超值价来袭
- 缤智多少钱 2025款落地价全解买车必看